
Which PDF Parser Should You Use?
Parsing information from PDFs isn’t just about extracting text anymore. For modern AI workflows, especially Retrieval-Augmented Generation (RAG), you need tools that can reliably understand complex layouts, tables, formulas, and even scanned images. Whether you’re building a chatbot, automating report processing, or structuring financial documents, the quality of your parser matters. We reviewed four leading open-source tools, Docling, Marker, MinerU, and olmOCR, and also looked at a commercial alternative, NetMind ParsePro. Here’s what you should know.
Comparison of Leading PDF Parsing Tools
Docling (IBM)
Best for: Enterprise knowledge pipelines
Inputs: PDF, DOCX, PPTX, HTML, images
Outputs: Markdown, HTML, JSON
Strengths:
- Modular analyzers for layout and tables
- Handles code and math formulas
- Integrates well with LlamaIndex and LangChain
ParsePro (NetMind)
Best for: High-volume, production-grade parsing with minimal setup
Inputs: PDF, DOCX, scanned documents
Outputs: Structured JSON, Markdown
Strengths:
- Hosted on H100/A100 GPUs
- Supports batch processing, document sharding, and async APIs
- Tuned for table extraction and layout accuracy in financial and enterprise use cases
Marker (DataLab)
Best for: Flexible format handling across languages
Inputs: PDF, DOCX, PPTX, XLSX, HTML, EPUB, images
Outputs: Markdown, HTML, JSON
Strengths:
- Multi-language OCR, table and formula extraction,
- Supports 90+ languages
- GPU-accelerated
MinerU (OpenDataLab)
Best for: Chinese, scientific, and financial documents
Inputs: PDF
Outputs: Markdown, JSON
Strengths:
- High table accuracy in Chinese/Asian documents
- Handles headers, footers, and rotated layouts effectively
olmOCR (AllenAI)
Best for: Multi-column and archival scans
Inputs: PDF, PNG, JPEG
Outputs: Plain text, Markdown
Strengths:
- Vision-language model (7B)
- Optimized for layout fidelity in low-quality scans
- Scalable on GPU
Performance and Use Case Summary
TED-Struct Benchmarks:
- Chinese documents: MinerU scored a perfect 1.000
- Japanese documents: MinerU outperformed Marker
- English documents: Mixed results—best tool depends on document structure
Pricing Comparison:
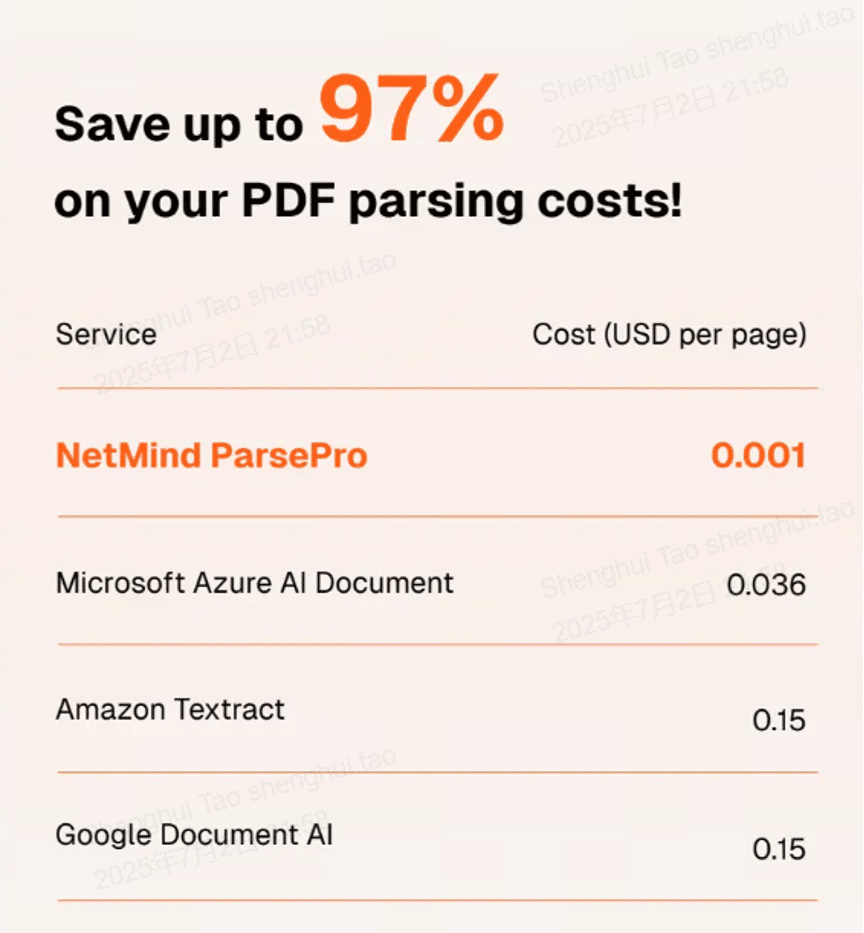
While the 4 open-source tools are clearly free, NetMind ParsePro is the cheapest among commercial choices, outcompeting others by up to 97%. In one cited case, a team cuts parsing costs from $12,000 to $1,200 per month while improving accuracy, from 85% to 87% on financial tables. (image from NetMind website).
Tool Selection by Scenario
No single parser is optimal across every workflow. Each tool brings specific strengths that may align better with certain document types, languages, or deployment needs. Below is a guide to selecting tools based on common scenarios:
- For high-throughput production environments: NetMind ParsePro is designed for teams who need scalable, consistent parsing without managing infrastructure. It suits workloads requiring batch processing, layout consistency, and encryption by default—especially in finance, compliance, or SaaS workflows.
- For enterprise knowledge pipelines: Use Docling if your focus is on downstream NLP integration with platforms like LangChain or LlamaIndex. It excels at extracting structure (e.g., reading order, code blocks, and math formulas) and is particularly effective when paired with existing knowledge graph or search stack tooling.
- For multilingual OCR and complex tables: MinerU is recommended for documents in Chinese, Japanese, or other non-English languages, especially where header/footer cleanup, rotated layouts, and large tables are involved. Its hybrid parsing architecture delivers strong accuracy in these domains.
- For broad format coverage and fast preprocessing: Choose Marker if your pipeline handles multiple input types (e.g., DOCX, XLSX, EPUB, and images). It offers fast performance, strong multi-language OCR, and flexible output formats—making it ideal for preprocessing diverse datasets at scale.
- For archival and low-quality scans: olmOCR is best suited for complex visual layouts, such as multi-column reports or scanned documents from legacy archives. Its vision-language model architecture enables layout fidelity in situations where traditional OCR tools struggle.
Hybrid Workflow Suggestion
In practice, teams often combine multiple tools to maximize both accuracy and coverage across different document types. One such workflow might look like this:
- Initial Conversion: Use Marker to rapidly convert a wide range of file types (PDF, DOCX, PPTX, HTML, etc.) into structured intermediate formats.
- Language- and Structure-Specific Refinement: Apply MinerU for post-processing on documents with non-English content or complex table structures. Its capabilities in rotated layouts and header/footer handling improve structural fidelity.
- Integration Layer: Utilize Docling as a final pass for aligning with downstream AI pipelines. Its structured output and NLP compatibility make it ideal for feeding into LLM-based systems or search layers.
- Production Alternative: If infrastructure setup is a constraint, or you prefer a plug-and-play approach, consider using NetMind ParsePro as a single-step parser. It provides consistent, structured outputs with minimal integration overhead, trading flexibility for ease and reliability.
While hybrid setups offer maximum control and fine-tuning potential, they also introduce deployment complexity. Commercial APIs like ParsePro can reduce engineering lift for teams focused on scaling quickly or working under compliance constraints.
Final Recommendation
If you have a highly specialized use case or prefer full control, open-source stacks like Marker, Docling, and MinerU are solid options, especially for experimentation or academic contexts.
But for production teams working at scale, the balance of cost, speed, and structure increasingly points to ParsePro. It eliminates the operational friction of managing pipelines while maintaining high output quality. For teams shipping AI products with document inputs, ParsePro isn’t just convenient—it’s the most efficient choice.